3D multi-object tracking (MOT) is an essential component of the scene understanding pipeline of autonomous robots. It aims at inferring associations between occurrences of object instances at different time steps in order to predict plausible 3D trajectories. These trajectories are then used in various downstream tasks such as trajectory prediction or navigation. Owing to recent advances in LiDAR-based object detection [1], the 3D tracking task has also seen significant performance improvements. Real-world deployment of these online methods in areas such as autonomous driving poses several challenges. When requiring regulatory approval, its robust behavior must be demonstrated on large sets of reference data which is arduous to obtain due to the lack of extensive ground truth. Therefore, performing high-quality offline labeling of real-world traffic scenes provides the means to test online methods on a larger scale and further sets a benchmark for what is within the realms of possibility for online methods.
3D Multi-Object Tracking Using Graph Neural Networks with Cross-Edge Modality Attention
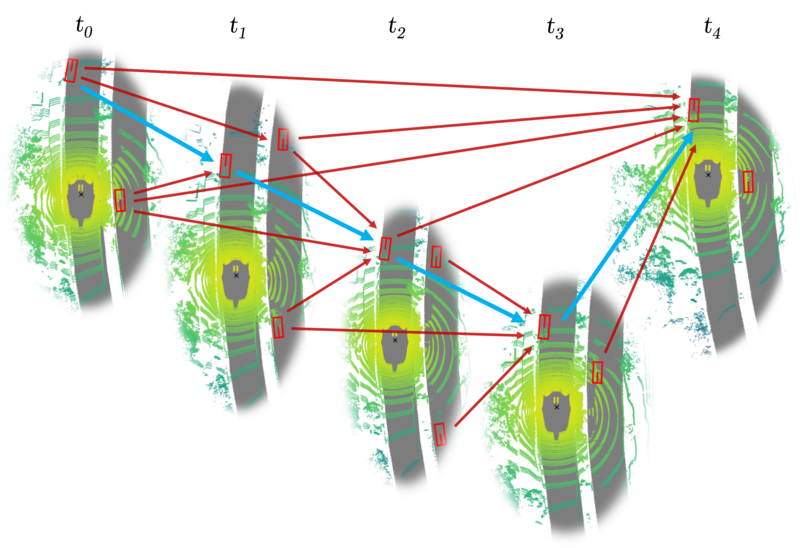
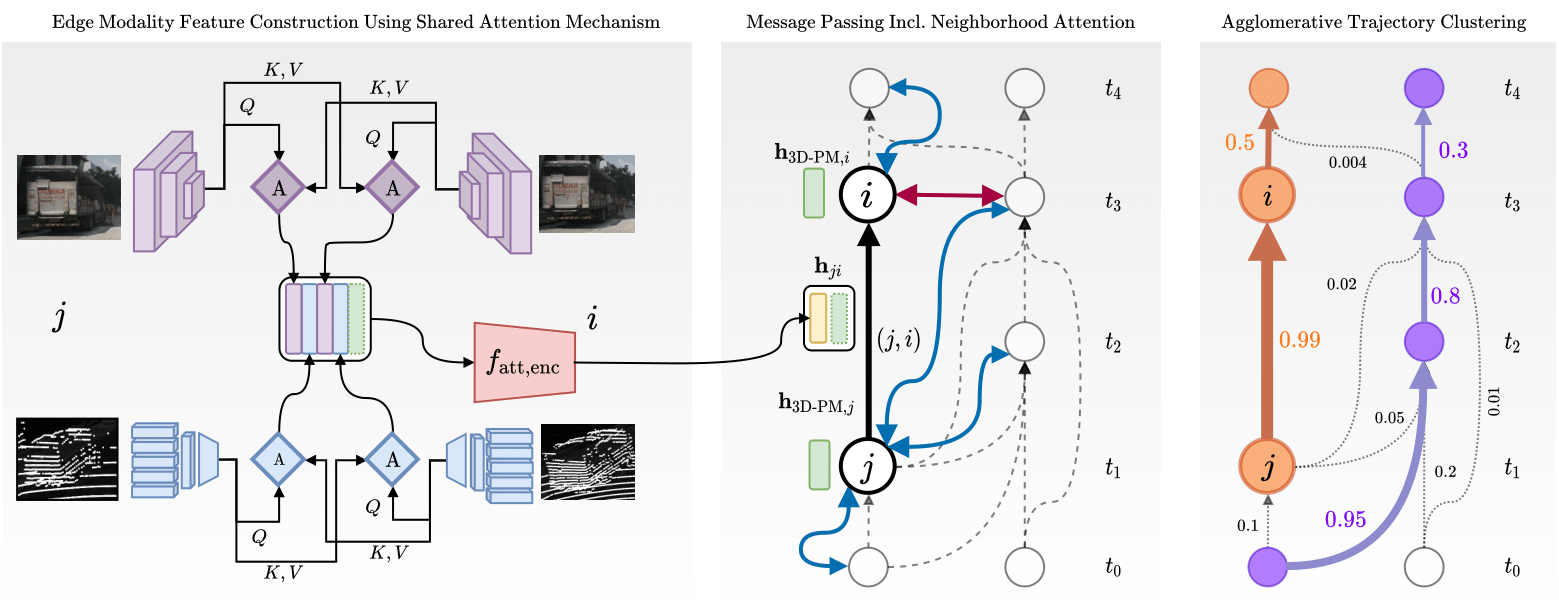
We present Batch3DMOT, an offline 3D tracking framework that follows the tracking-by-detection paradigm and utilizes multiple sensor modalities (camera, LiDAR, radar) to solve a multi-frame, multi-object tracking objective. Sets of 3D object detections per frame are first turned into attributed nodes. In order to learn offline 3D tracking, we employ a graph neural network (GNN) that performs time-aware neural message passing with intermediate frame-wise attention-weighted neighborhood convolutions. Different from popular Kalman-based approaches, which essentially track objects of different semantic categories independently, our method uses a single model that operates on category-disjoint graph components. As a consequence, it leverages inter-category similarities to improve tracking performance.
When evaluating typically used modalities such as LiDAR,we can make a striking observation: On the one hand, detection features such as bounding box size or orientation are consistently available across time. A similar observation can be made for camera features, even if the object is (partially) occluded. On the other hand, sensor modalities such as LiDAR or radar do not necessarily share this availability. Due to their inherent sparsity, constructing a feature, e.g., for faraway objects, is typically impractical as it does not serve as a discriminative feature that can be used in tracking. This potential modality intermittence translates to sparsity in the graph domain, which is tackled in this work using our proposed cross-edge modality attention. This enables an edge-wise agreement on whether to include the particular modality in node similarity finding.